
上一篇介绍了JavaAPI以及基本Shell指令,这一篇我们将介绍HBase内部表原理以及拆分操作
hbase(main):013:0> scan 'hbase:meta'
这个指令我们可以看出scan扫描hbase名称空间下的meta表,
返回列加Cell。rowKey为唯一的,info为列族,:regioninfo为列名。1
2
3
4
5
6timestamp这个时刻该行的的cell的值格式(都是key=>value对 ','分割) 或者单独的一个值,val=xxx :
value={EN
3498206.ab1abd27f20f CODED => ab1abd27f20f79ca240e5dd9576317d4,
NAME => 'f_newa
79ca240e5dd9576317d4 pi_wyc,,1505713498206.ab1abd27f20f79ca240e5dd9576317d4.',
. STARTKEY => '', ENDKEY => ''} 开始行和结束行 STARTKEY/ENDKEY 表示从哪开始 到哪结束。
时间戳的意思就是一个value可能是有很多版本的,默认显示的是最新时间戳的版本cell的值。
这里查询meta得到的所有信息都是这一张表的一个区域Region信息。这样的好处在于: 每次Get 请求查询的时候 不需要先去RS中查询,而是先来meta这里查询请求信息里的表和列族是在哪一个RegionServer中,查询到以后直接就去指定的RegionServer中的Region查询数据并立即返回,提升性能。
HBase Table拆分合并原理实践
虽说Hbase会对分区进行自动拆分和合并,但是我们也可以手动显式地调用拆分和合并操作。
HBase Shell 下的 split指令
hbase(main):014:0> help 'split'
1 | Split entire table or pass a region to split individual region. With the |
可以直接切割一张表,名称空间:表、还可以切割定制分区以及指定切割的键
例如我们这里直接切割表:
输入切割指令:hbase(main):021:0> split 'f_newapi_wyc'
再scan查询 ‘hbase:meta’
切割表后查询发现已经有4行数据了,我们可以通过管道来重定向到一个文本文件中。quanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ echo "scan 'hbase:meta'" | hbase shell > hbase_meta.txt
echo 输出指令 带有查询元数据的指令 作为hbase shell指令的输入 最后重定向到hbase_meta.txt文件中去。gedit hbase_meta.txt 查看即可发现输出元数据已经在文本文件里了 这个。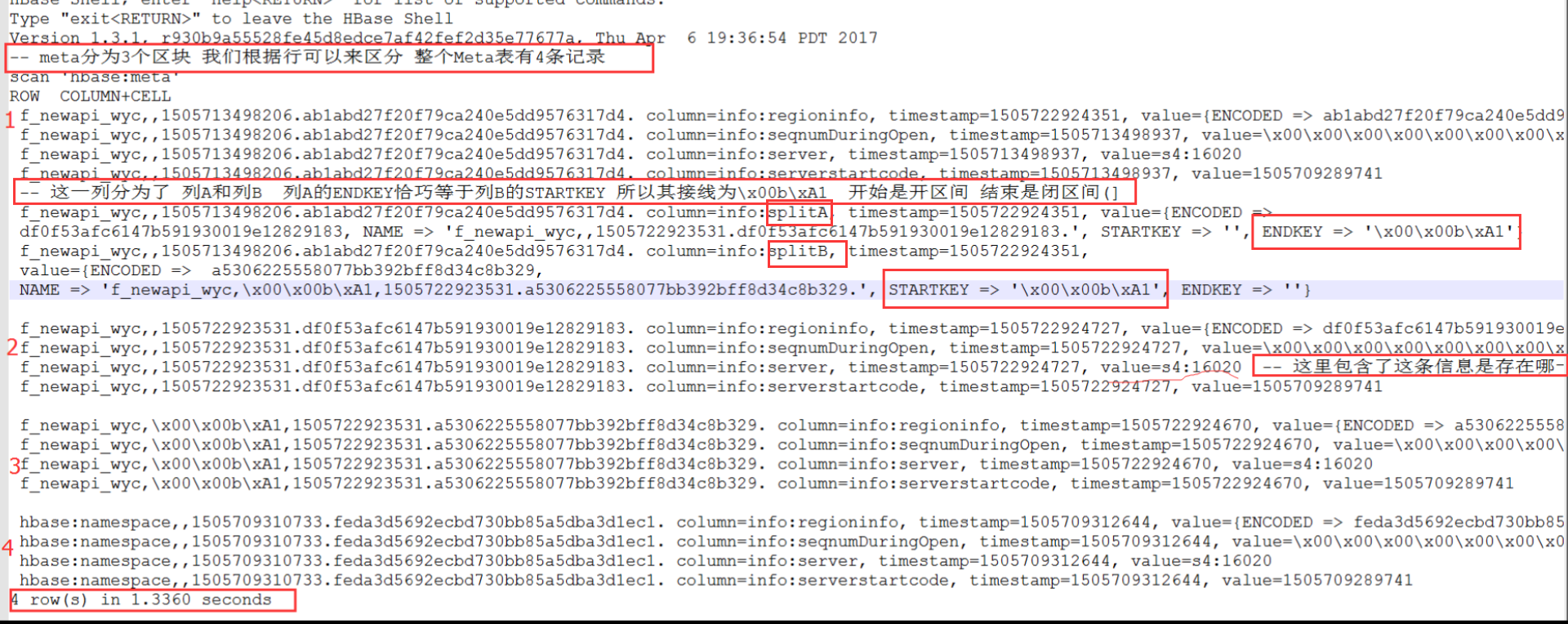
这里的A 和B 就是我们刚刚Split切割出来的。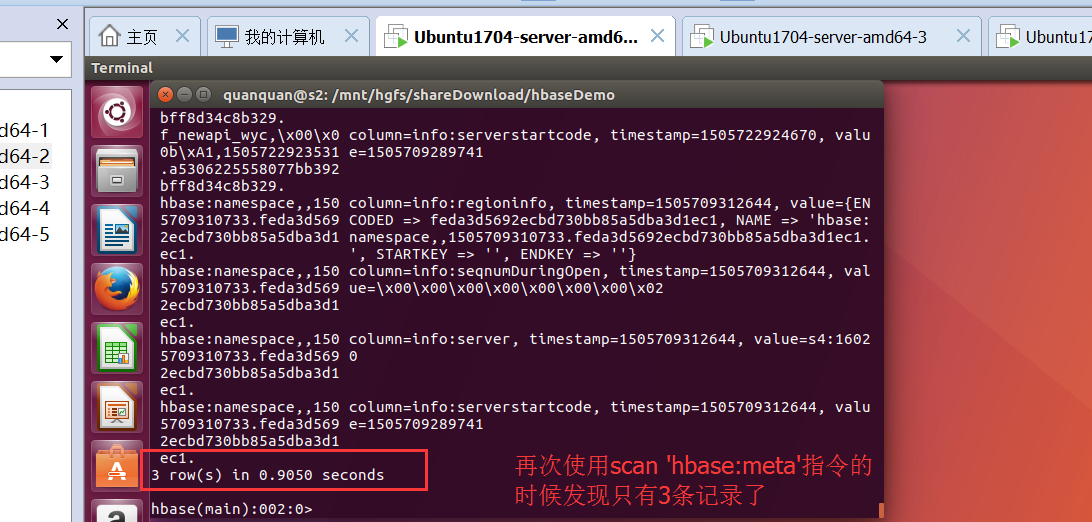
我们导出的文件可以看出,第一次4row只是还没拆分完成,拆后会删除那个分开的region 并将拆后数据重新分配到一个RS上,所以不存在SplitA和SplitB这两个区域和其所在的分区。
HBase Table 合并
既然刚刚可以拆分表,那么也可以合并区域Region。hbase(main):001:0> help 'merge_region'1
2
3Merge two regions. Passing 'true' as the optional third parameter will force
a merge ('force' merges regardless else merge will fail unless passed
adjacent regions. 'force' is for expert use only).
合并2个分区,通过可选的第三个参数’true’ 来强制合并,(强制合并无论如何都会合并否则失败,只建议专业用途来使用)。1
2
3
4
5NOTE: You must pass the encoded region name, not the full region name so
this command is a little different from other region operations. The encoded
region name is the hash suffix on region names: e.g. if the region name were
TestTable,0094429456,1289497600452.527db22f95c8a9e0116f0cc13c680396. then
the encoded region name portion is 527db22f95c8a9e0116f0cc13c680396
Examples:
hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME'hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME', true
这里注意是要传入其ENCODED_REGIONNAME,:
hbase(main):003:0> merge_region 'df0f53afc6147b591930019e12829183','a5306225558077bb392bff8d34c8b329'0 row(s) in 1.7300 seconds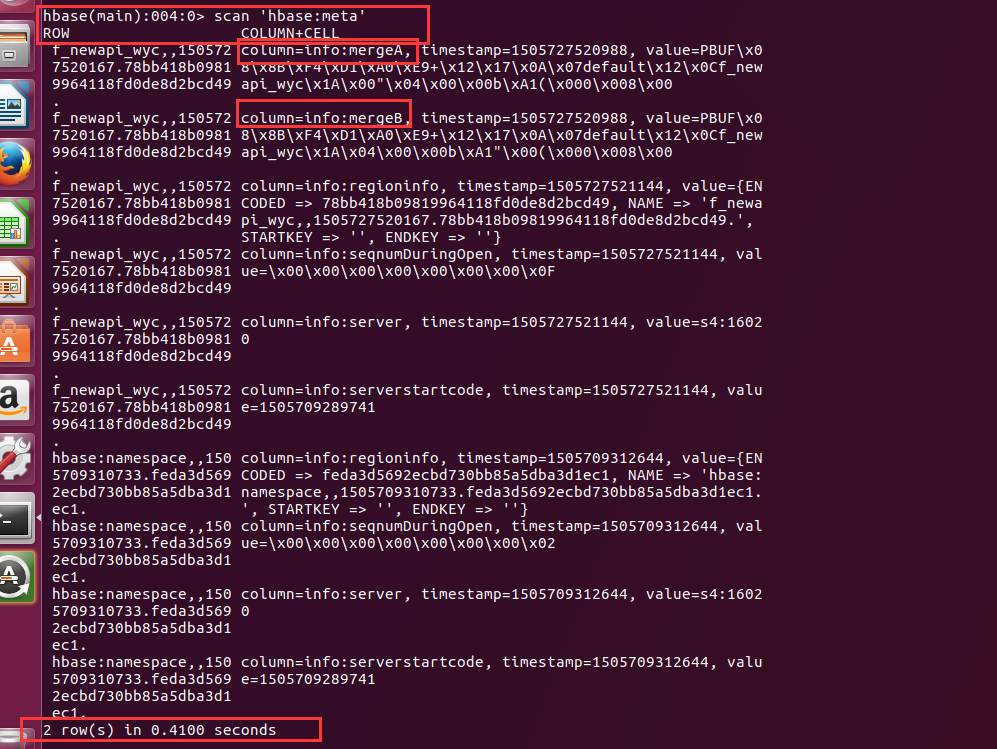
可以看到合并后生成了新的MergeA和MergeB,合并生成了新的Region分区。A,B块同切割块一样,代表正在合并。
再次键入命令查询: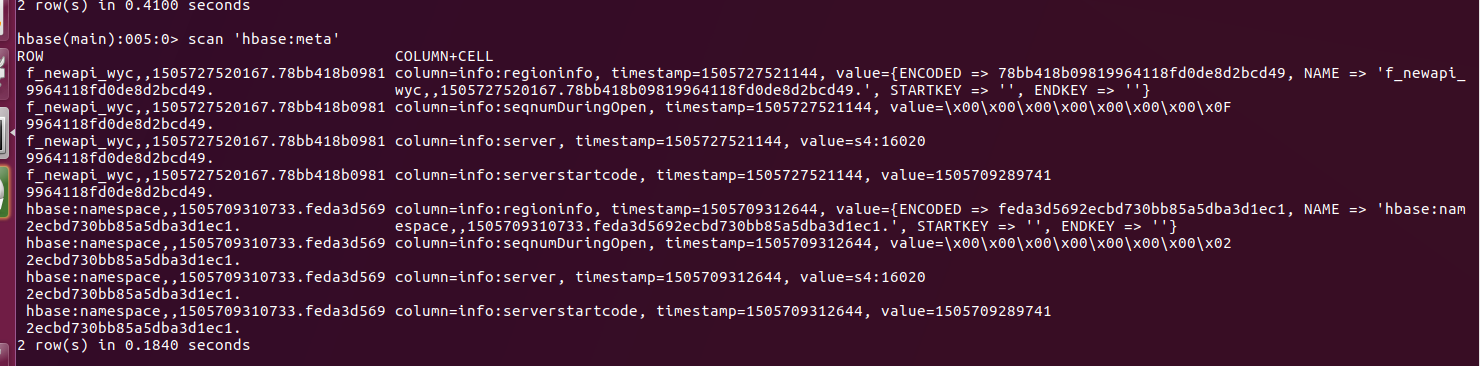
startKey和endKey均为空 代表已经合并完了。
编程式切割HBase表
编程式调用HBase切割操作:
我们创建一个类,com.wyc.hbase.newapi.HBaseSplitApp:
1 | package com.wyc.hbase.newapi; |
执行切割表代码前操作:
scan ‘hbase:meta’
quanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ export HBASE_CLASSPATH=HBaseSplitTableDemo.jarquanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ hbase com.wyc.hbase.newapi.HBaseSplitApp
调用切割表指令后:
现在再次输入 scan ‘hbase:meta’ 发现4行 代表正在切割(SplitA和SplitB块):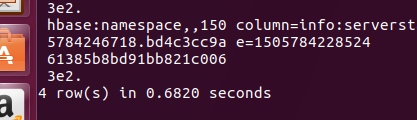
现在显示只剩3行代表切割完成。SPlitA和B块已合并。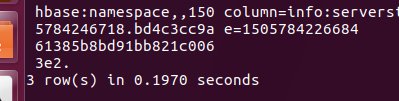
quanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ export HBASE_CLASSPATH=HBaseMergeTableDemo.jarquanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ hbase com.wyc.hbase.newapi.HBaseSplitApp
调用合并代码后: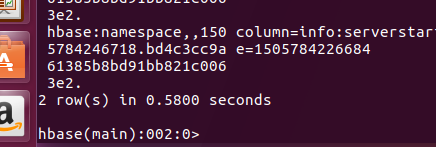
hbase(main):002:0> scan ‘hbase:meta’
分区合并了,所以一共2行了,合并OK。
现在来测试切割分区操作:hbase(main):002:0> scan 'hbase:meta'1
2
3
4
52rows:
f_newapi_wyc,,150578 column=info:regioninfo, timestamp=1505785544127, value={EN
5543601.bfc156cd7e3b CODED => bfc156cd7e3b50c991ce178edf8f976d, NAME => 'f_newa
50c991ce178edf8f976d pi_wyc,,1505785543601.bfc156cd7e3b50c991ce178edf8f976d.',
. STARTKEY => '', ENDKEY => ''}
运行切割分区jar:quanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ export HBASE_CLASSPATH=HBaseSplitRegionDemo.jar
quanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ hbase com.wyc.hbase.newapi.HBaseSplitApp
现在查看 正在切割中 4rows: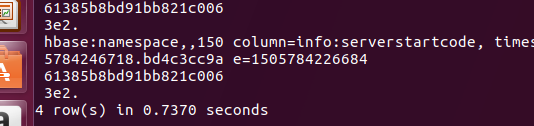
过一会再次查看 可以发现只剩3行数据了 切割完成: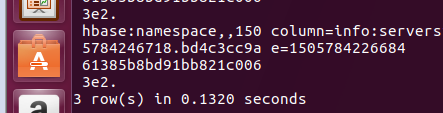
切割分区也OK。
好了,关于HBase一系列基本操作就介绍到这里了,有问题可以。