
Hbase简介
HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase以表的形式存储数据。表由行和列组成。列划分为若干个列族(row family)。
结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。
非结构化数据:包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
半结构化数据:就是介于完全结构化数据(如关系型数据库、面向对象数据库中的数据)和完全无结构的数据(如声音、图像文件等)之间的数据,HTML文档就属于半结构化数据。它一般是自描述的,数据的结构和内容混在一起,没有明显的区分。
HBase在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来访问数据,也可以通过REST、Avro或者Thrift的API来访问。
虽然最近性能有了显著的提升,HBase 还不能直接取代SQL数据库。如今,它已经应用于多个数据驱动型网站,包括 Facebook的消息平台。
特点:
- 面向列的数据库
- 基于内存的(效率高)
- 定义表时不指定字段
- 定义表的时候只要指定列族名,列族数量不限
- 每一行都有一个固定的字段(行键),具有唯一性
- 对值的修改,原来的值是保留着的,每个值可以保留多个版本。默认查询的是最新版本的的值。(默认保留一个版本)
典型的案例来说就是以前使用的Excel表格来存储列的数据: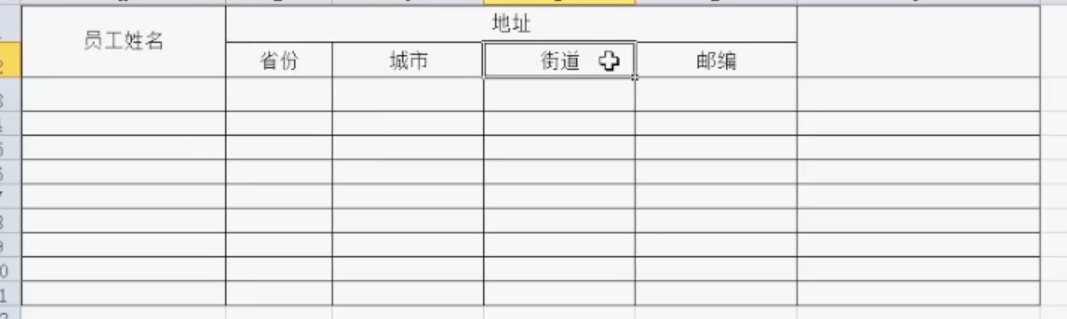
Apache HBase最初是Powerset公司为了处理自然语言搜索产生的海量数据而开展的项目。不过现在它已经是Apache基金会的顶级项目,并且引起了广泛的关注。
Facebook在2010年11月选用了HBase来实现它新的消息平台。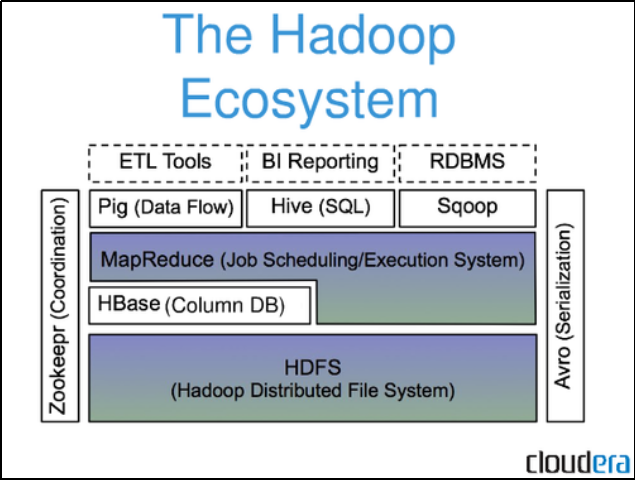
HBase中的重要概念
列族 :hbase表中的每个列,都归属与某个列族。列族是表的chema的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history , courses:math 都属于 courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因 为隐私的原因不能浏览所有数据)。
时间戳 :HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
Cell :由{row key, column( =
HBase体系结构
1、一个表会按照行划分为若干个region,每一个region分配给一台特定的regionserver管理
2、每一个region内部还要依据列族划分为若干个HStore
3、每个HStore中的数据会落地到若干个HFILE文件中
4、region体积会随着数据插入而不断增长,到一定阈值等值分裂
5、随着region的分裂,一台regionserver上管理的region会越来越多
6、HMASTER会根据regionserver上管理的region数做负载均衡
7、region中的数据拥有一个内存缓存:memstore,数据的访问优先在memstore中进行
8、memstore中的数据因为空间有限,所以需要定期flush到文件storefile中,每次flush都是生成新的storefile
9、storefile的数量随着时间也会不断增加,regionserver会定期将大量storefile进行合并(merge)
行键的设计对数据查询效率的影响非常大。
HBase具有很好的可伸缩性:如果存储容量不够的时候,直接加datanode或者regionservers
hbase可以作为一个线上系统的底层系统的功能。
Hmaster可以做负载均衡,监控到各个节点之间的数据存储情况。
每一个store(列族)会有一个内存缓存,存放的是一些最热的数据(最近访问的),这样的话读取数据的速度会快很多。
文件都是有索引的,所以查起来会比较快的。
region会在storefile定期进行合并操作。
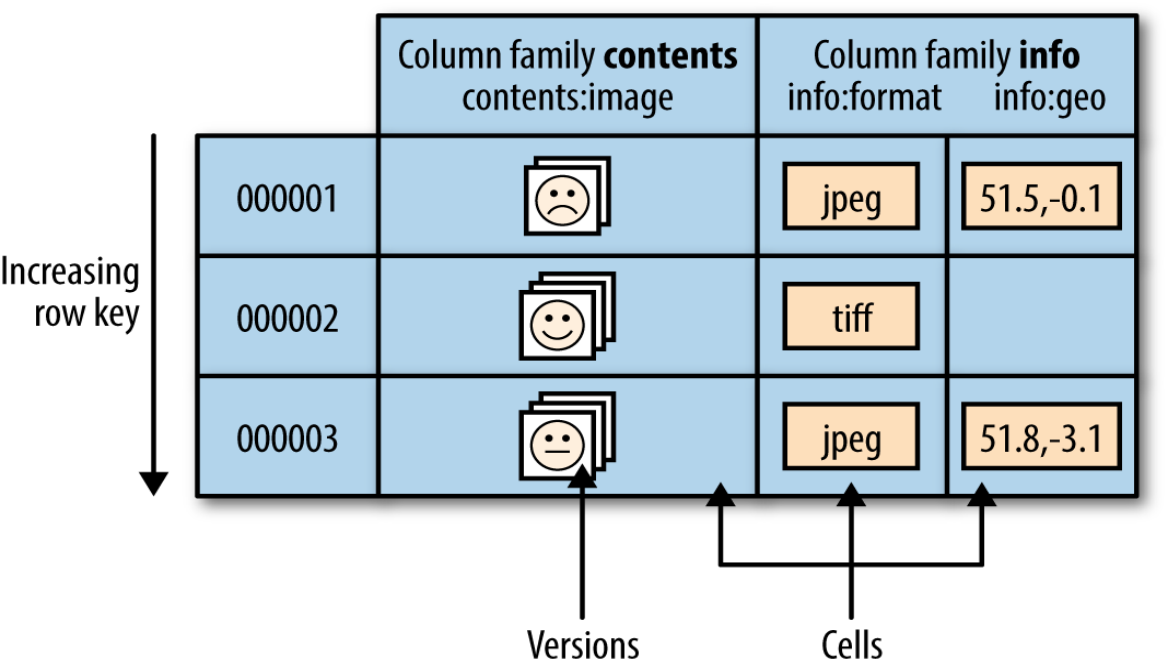
小结 :
HBase 分区 Region关键点:
- 自动水平分区
- row的子集 每一个分区都是一个行的子集
- 第一行(include),最后一行(exclude)
- 每张表至少一个region分区
- 增长到阀值时,切割成两个相同的分区region
- row update行更新是原子性的
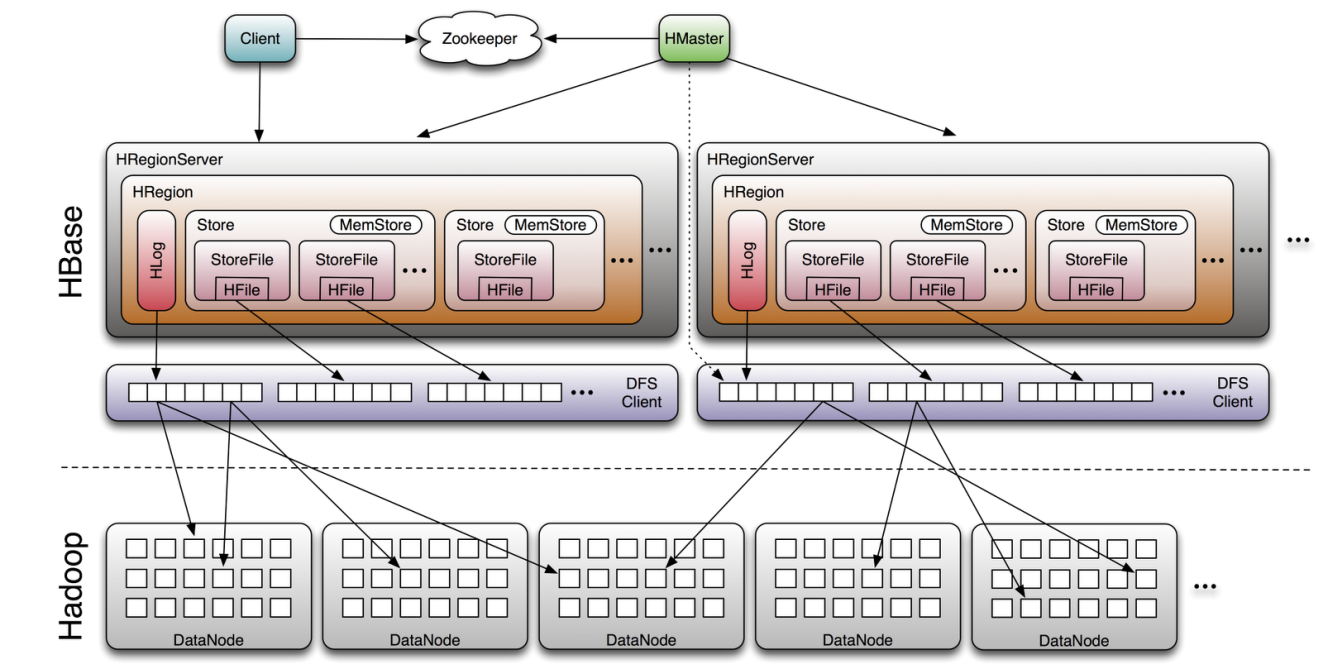
Hbase构成简述
- Hbase master(1)
- 负责初始安装
- 指定分区region到分区服务器regionserver
- 恢复故障的分区服务器ReginServer
- 轻负载
- Hbase依赖于zookeeper(分布式服务协同组件)
- 默认HBase管理zookeeper start/stop 启动或者停止
- HMaster和HRS在zookeeper中进行注册
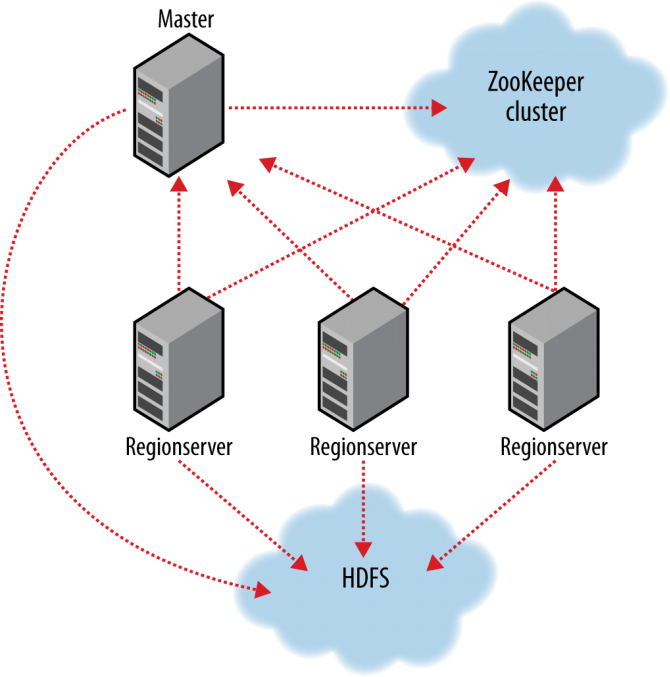
Hbase ReginServer(n) Hbase 的分区服务器
- 一个分区服务器会携带0~n个分区region
- 负责客户端读写请求。
- 管理分区切割(表增长到一定的阈值就分割成2个相同的表)region split
- 通知Hbase master新的子分区在哪里
- 管理离线的父代分区以及对其的替换。
下一篇将介绍HBase的安装和体验。